My name is Hao Shi (石昊), a third-year Master’s student in the Department of Automation at Tsinghua University, in a joint program with MEGVII Research, advised by Prof. Gao Huang and Xiangyu Zhang, and I also work closely with Tiancai Wang.
Before that, I received my Bachelor’s degree in Computer Science from Tianjin University in 2023, advised by Prof. Di Lin.
My research focuses on Embodied AI, Robot Learning, VLA, and 3D Perception, aiming to build foundation models for general robotic systems.
I am expected to join HKU MMLab as a Ph.D. student advised by Prof. Ping Luo in Fall 2026.
📖 Education
M.Eng. in AI, Department of Automation, Tsinghua University, Beijing.
Advisors: Prof. Gao Huang and Xiangyu Zhang
GPA: 3.8 / 4.0
B.Eng. in Computer Science, Tianjin University.
Academic advisor: Prof. Di Lin
GPA: 3.81 / 4.0, 91.2 / 100
B.Eng. student in Materials Science, Tianjin University.
📝 Research
Selected Works
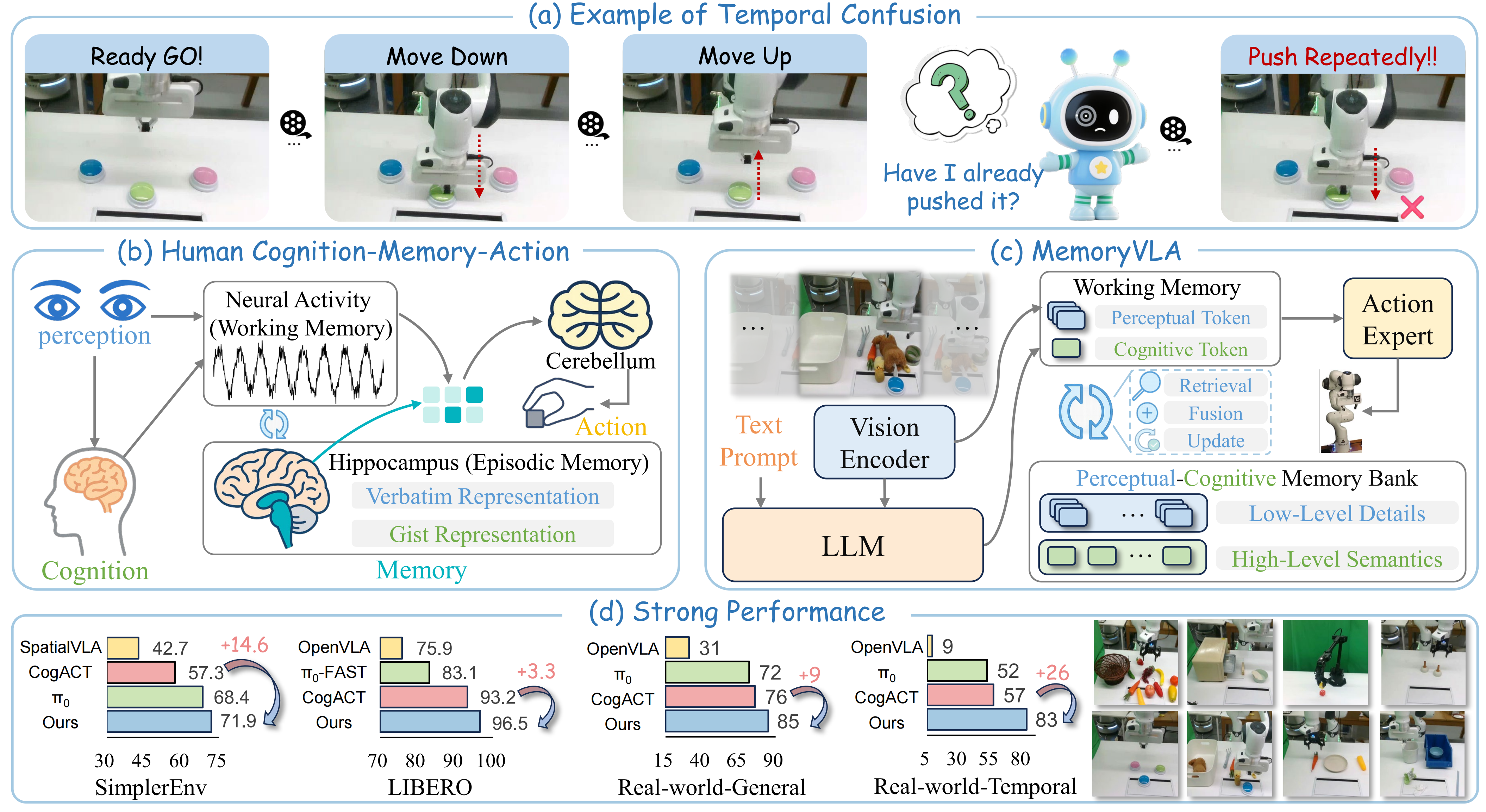
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xiangyu Zhang, Gao Huang✉
- MemoryVLA is a Cognition-Memory-Action framework for robotic manipulation inspired by human memory systems. It builds a hippocampal-like perceptual-cognitive memory to capture the temporal dependencies essential for current decision-making, enabling long-horizon, temporally aware action generation.
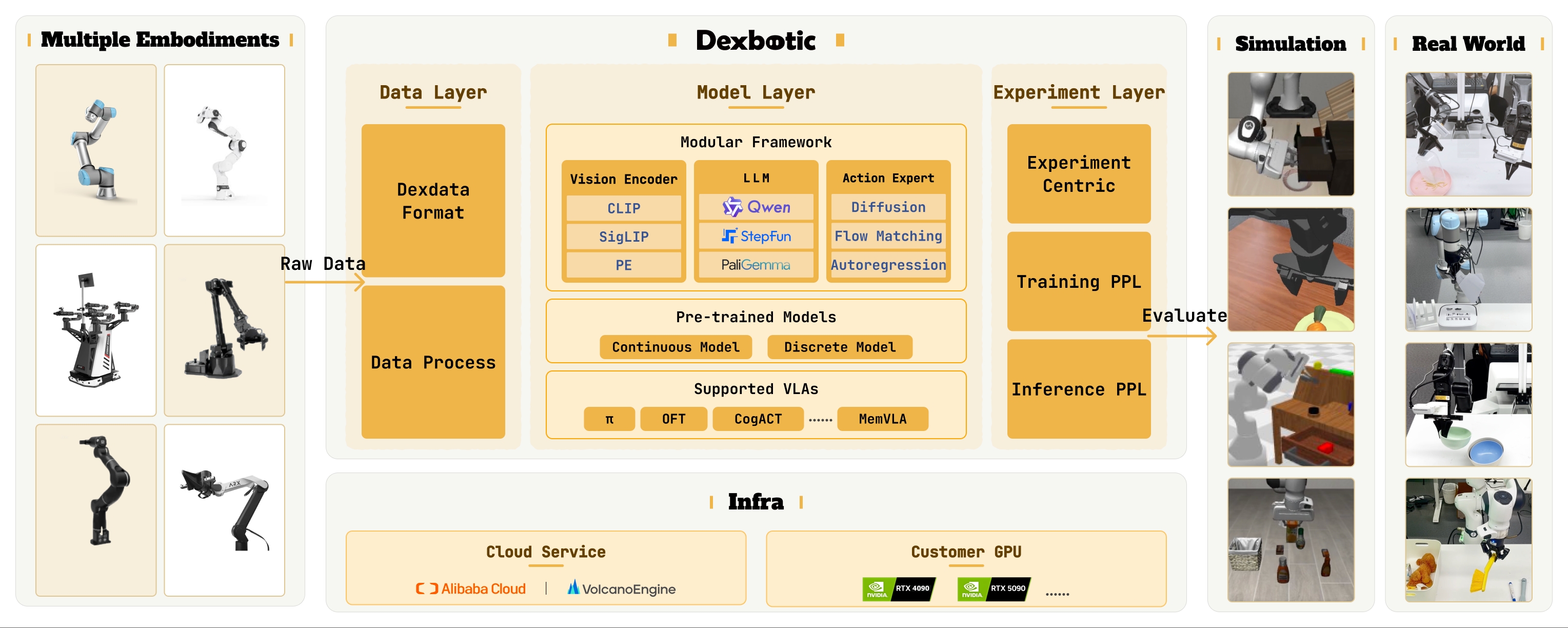
Dexbotic: Open-Source Vision-Language-Action Toolbox
Dexbotic Team
- Dexbotic is an open-source VLA toolbox for embodied AI research (similar to MMDetection). It provides a unified and experiment-centric codebase that supports multiple mainstream VLA frameworks and benchmarks within a single environment, and offers stronger pretrained models.
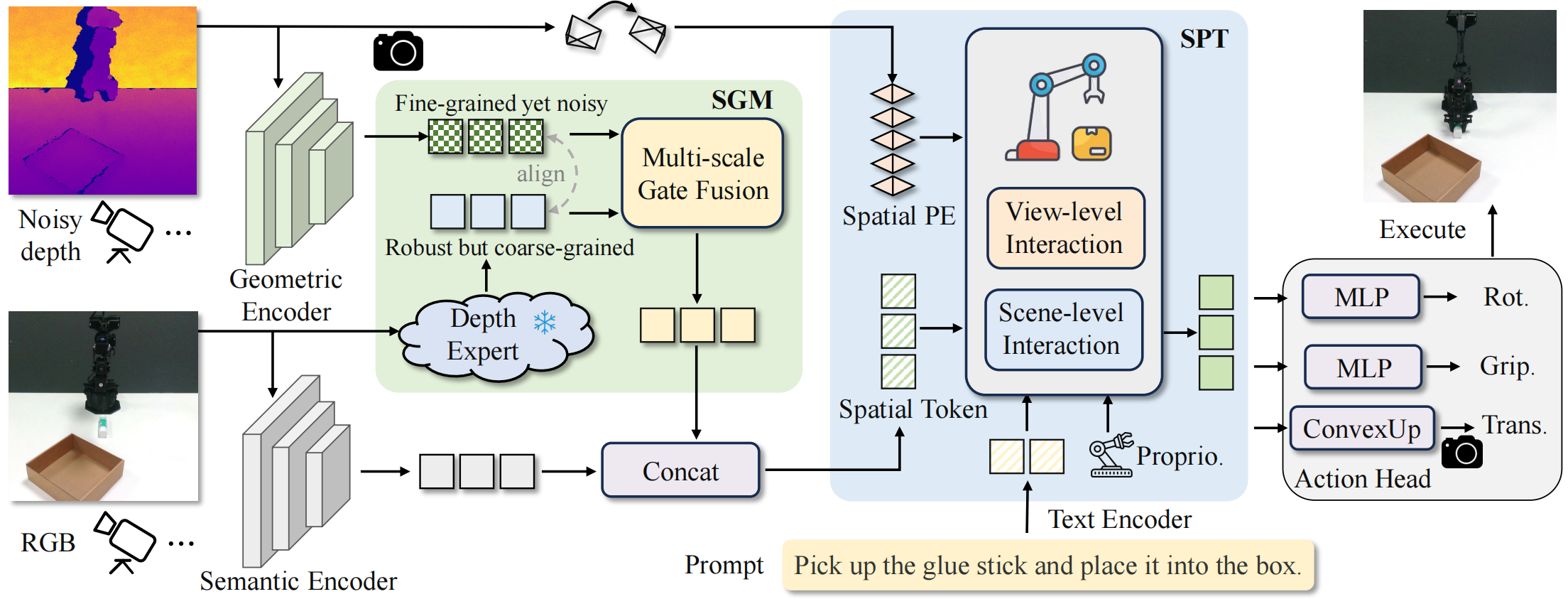
SpatialActor: Exploring Disentangled Spatial Representations for Robust Robotic Manipulation
Hao Shi, Bin Xie, Yingfei Liu, Yang Yue, Tiancai Wang, Haoqiang Fan, Xiangyu Zhang, Gao Huang✉
- SpatialActor is a disentangled framework for robust robotic manipulation. It decouples perception into complementary high-level geometry from fine-grained but noisy raw depth and coarse but robust depth expert priors, along with low-level spatial cues and appearance semantics.
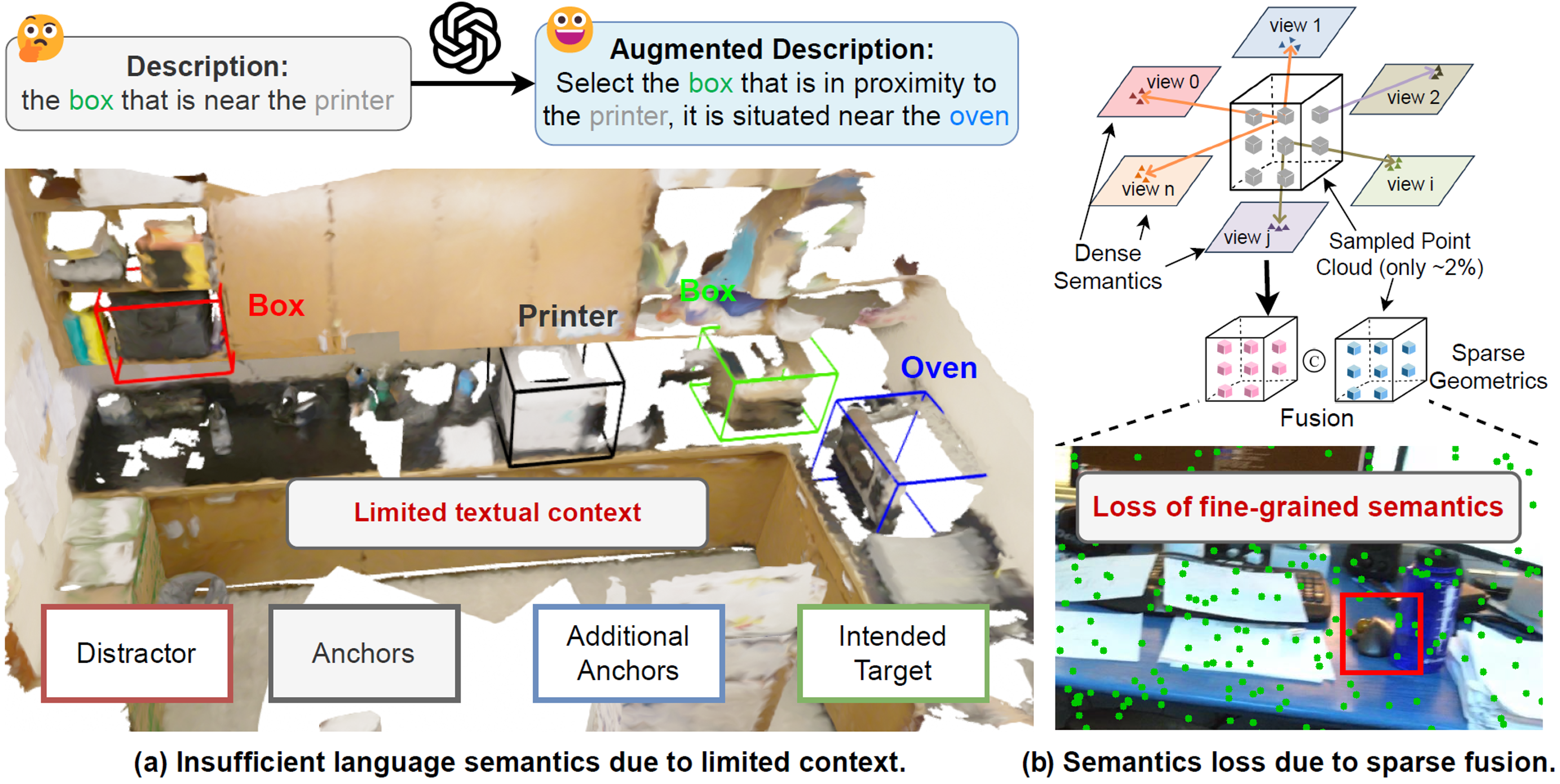
DenseGrounding: Improving Dense Language-Vision Semantics for Ego-centric 3D Visual Grounding
Henry Zheng*, Hao Shi*, Qihang Peng, Yong Xien Chng, Rui Huang, Yepeng Weng, Zhongchao Shi, Gao Huang✉
*: equal contribution, ✉: corresponding author.
- DenseGrounding is a framework for embodied 3D visual grounding. It tackles the loss of fine-grained visual semantics from sparse fusion of point clouds with multi-view images, as well as the limited textual semantic context from arbitrary instructions, enabling more accurate and context-aware grounding.
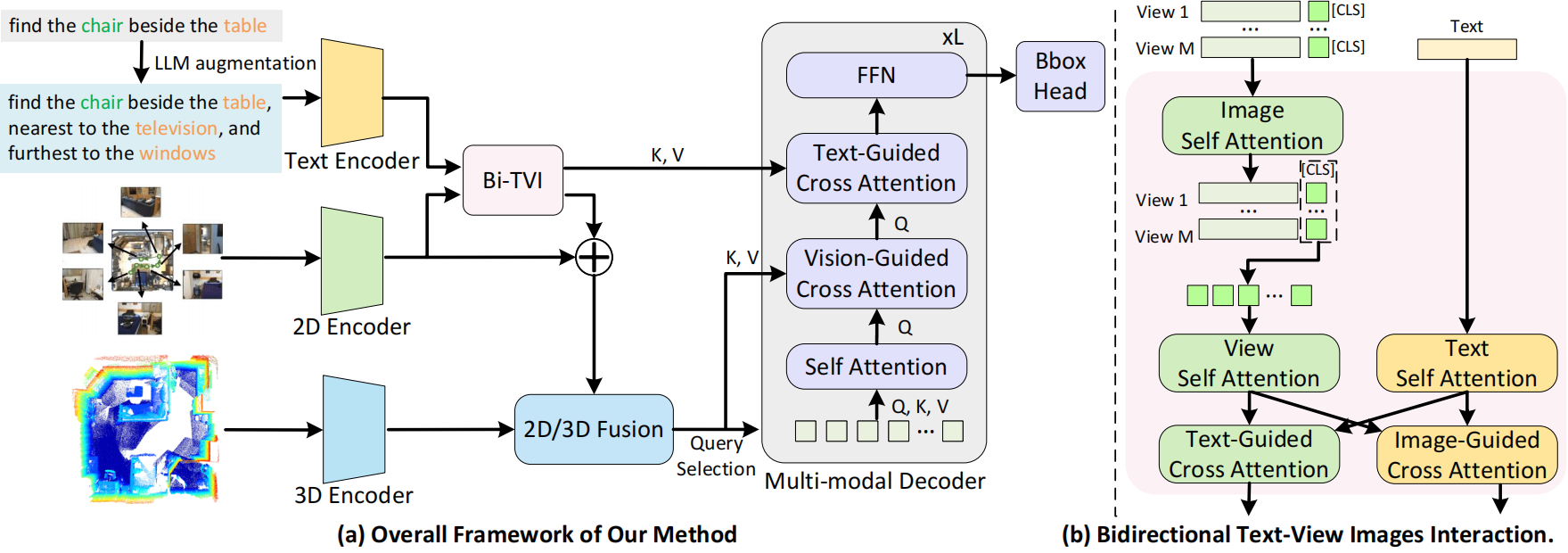
DenseG: Alleviating Vision-Language Feature Sparsity in Multi-View 3D Visual Grounding
Henry Zheng*, Hao Shi*, Yong Xien Chng, Rui Huang, Zanlin Ni, Tianyi Tan, Qihang Peng, Yepeng Weng, Zhongchao Shi, Gao Huang✉
*: equal contribution, ✉: corresponding author.
- 1st Place and Innovation Award in CVPR 2024 Autonomous Grand Challenge, Embodied 3D Grounding Track (1/64 teams, 1/154 submissions).
- Oral Presentation at CVPR 2024 Workshop on Foundation Models for Autonomous Systems.
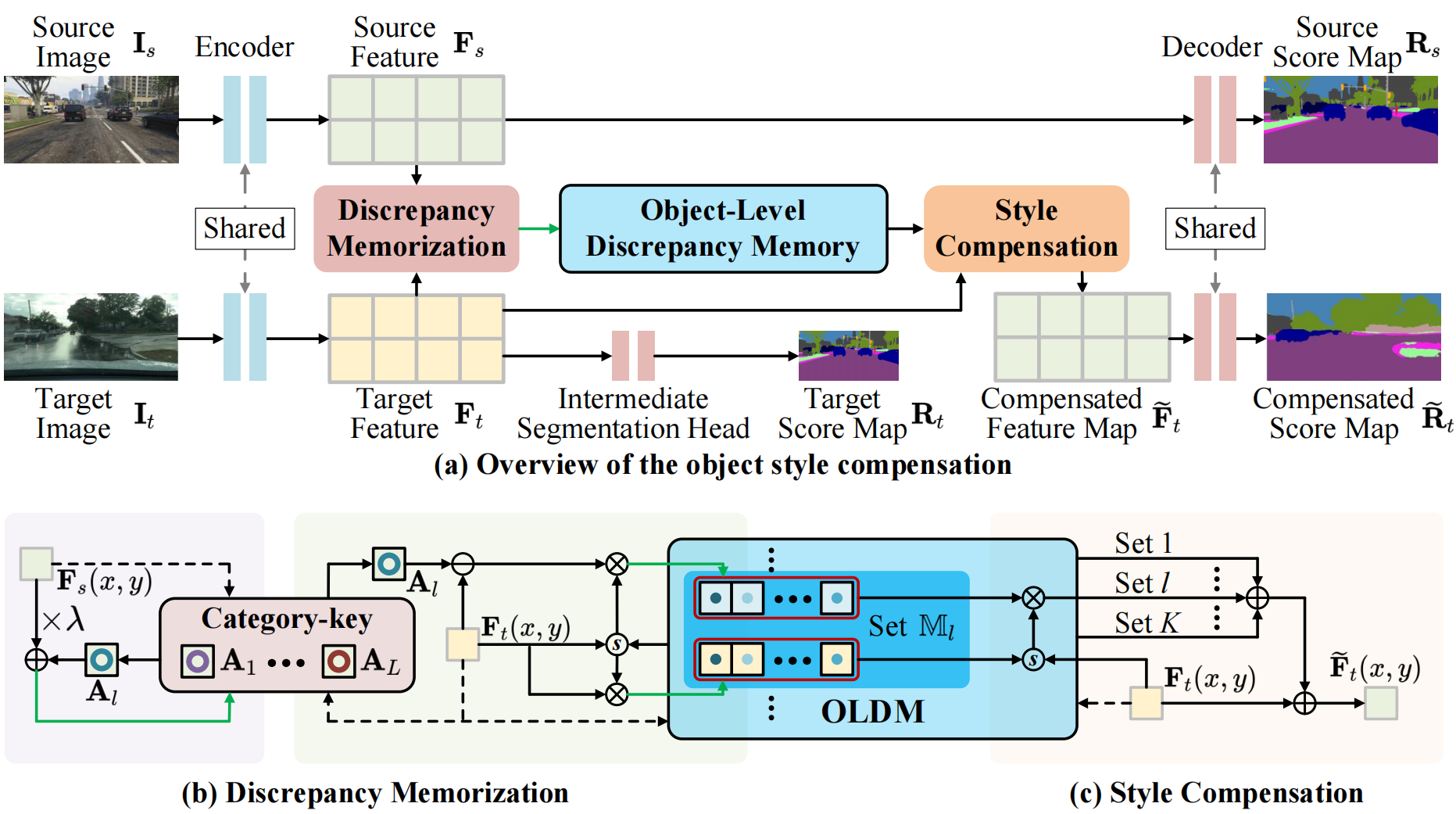
Open Compound Domain Adaptation with Object Style Compensation for Semantic Segmentation
Tingliang Feng*, Hao Shi*, Xueyang Liu, Wei Feng, Liang Wan, Yanlin Zhou, Di Lin✉
*: equal contribution, ✉: corresponding author.
- We propose object style compensation for open compound domain adaptation. It builds an object-level discrepancy memory bank to capture fine-grained source–target domain gaps and compensates target features to align with source distribution, enabling cross-domain segmentation.
Other Works
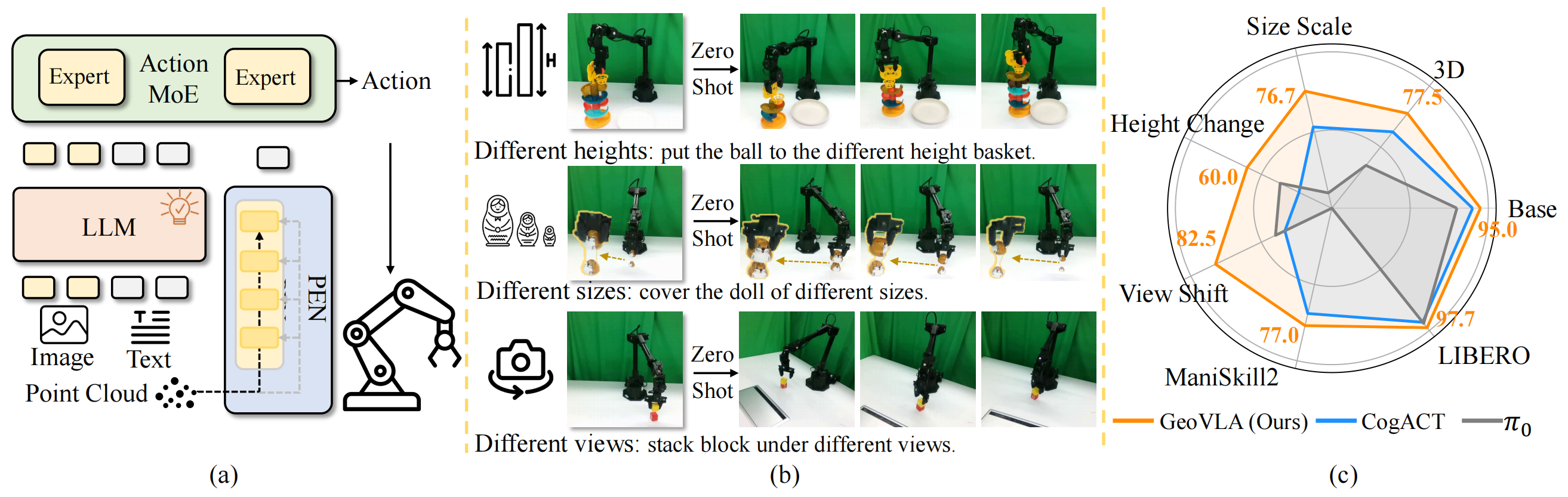
GeoVLA: Enpowering 3D Representations in Vision-Language-Action Models
Lin Sun*, Bin Xie*, Yingfei Liu, Hao Shi, Tiancai Wang, Jiale Cao✉
- GeoVLA is a framework that bridges 2D semantics and 3D geometry for VLA. By encoding geometric embeddings with a dual-stream design and leveraging a Mixture-of-Experts 3D-Aware Action Expert, it achieves robustness across diverse camera views, object heights, and sizes.
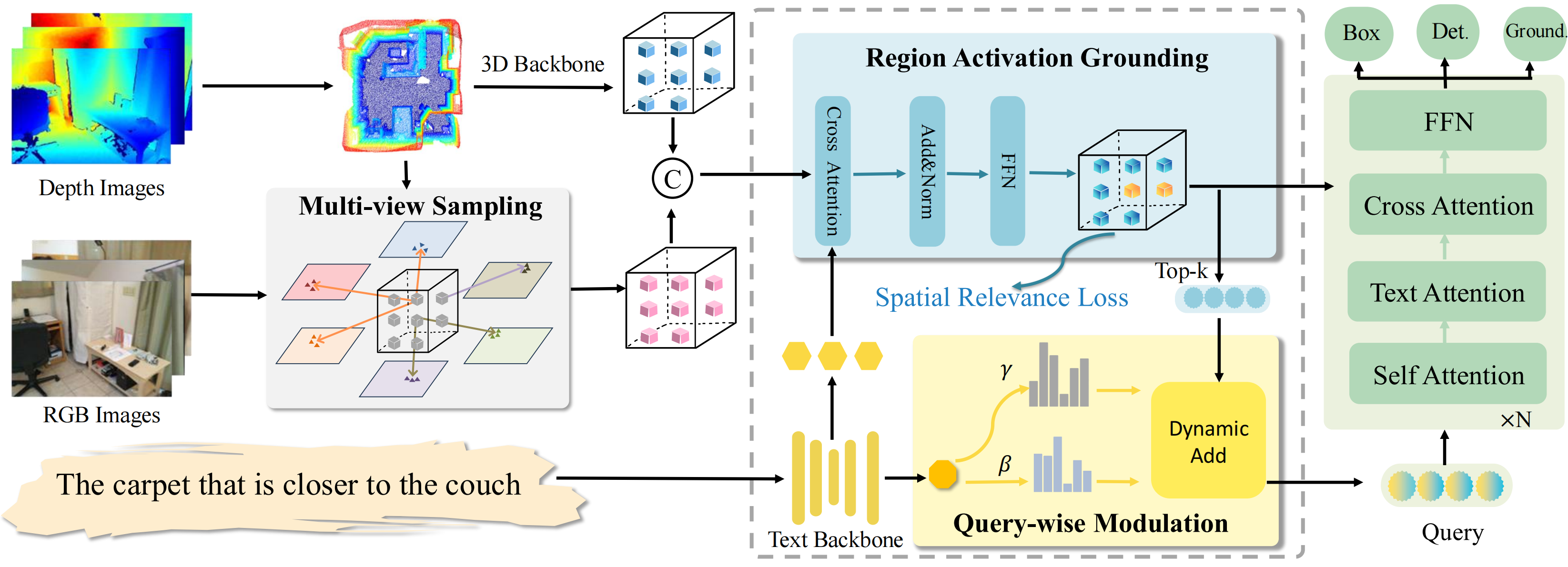
Grounding Beyond Detection: Enhancing Contextual Understanding in Embodied 3D Grounding
Yani Zhang*, Dongming Wu*, Hao Shi, Yingfei Liu, Tiancai Wang, Haoqiang Fan, Xingping Dong✉
- DEGround transfers general proposals from detection into grounding with shared queries, and mitigates vision–language misalignment through region activation and query-wise modulation, achieving 1st place on EmbodiedScan.
🎖 Honors and Awards
- 2025.11, Minghong Scholarship, Comprehensive Excellence 1st Prize, Tsinghua University. (Top 10% in THU, ¥10000)
- 2024.11, Philobiblion Scholarship, Comprehensive Excellence 1st Prize, Tsinghua University. (Top 10% in THU, ¥10000)
- 2024.06, 1st Place and Innovation Award in CVPR 2024 Autonomous Grand Challenge, Embodied 3D Grounding Track. (1/154 submission, $9000)
- 2023.11, CXMT Scholarship, Comprehensive Excellence 1st Prize, Tsinghua University. (Top 10% in THU, ¥10000)
- 2023.06, Outstanding Bachelor’s Thesis Award, Tianjin University.
- 2023.06, Excellent Graduate Award, Tianjin University.
- 2021.12, Ministry of Education-Huawei Intelligent Base Future Stars.
- 2021.12, Huawei Intelligent Base Scholarship.
💻 Internship
Dexmal, Beijing
Department: Embodied Foundation Research Group
Mentors: Tiancai Wang, Yingfei Liu and Bin Xie
MEGVII, Beijing
Department: Foundation Model Group
Mentors: Tiancai Wang and Yingfei Liu
💬 Invited Talks
- 2025.09, invited talk about MemoryVLA, 3D视觉工坊, Online
- 2025.09, invited talk about MemoryVLA, 具身智能之心, Online
- 2024.06, invited talk about DenseGrounding, CVPR 2024 Workshop on Foundation Models for Autonomous Systems, Seattle
- 2024.06, invited talk about DenseGrounding, Technical Seminar on End-to-End Embodied Agent, Shanghai
🎓 Service
Reviewer / PC Member:
- ICLR 2026, ICLR 2025
- AAAI 2026
- ICCV 2025